Automated PII Redaction in Financial Data: Ensuring Compliance
Financial institutions handle voluminous documents, including sensitive loan and mortgage statements with confidential customer data. Upholding data protection is crucial for compliance with regulations like the California Consumer Privacy Act (CCPA), Europe’s GDPR, and Payment Card Industry Data Security Standards (PCI DSS).
Navigating Data Protection Challenges
Manually redacting documents, whether digital or physical, is time-consuming and risks inadvertent information release in financial institutions. To mitigate these challenges, automated processes significantly reduce data breach risks.
Harnessing AWS Services for Enhanced Security
In this post, we explore the automatic redaction of personally identifiable information (PII) using the machine learning capabilities of Amazon Comprehend and Amazon Athena in financial services (FinServ) data.
Safeguarding Data and Ensuring Compliance
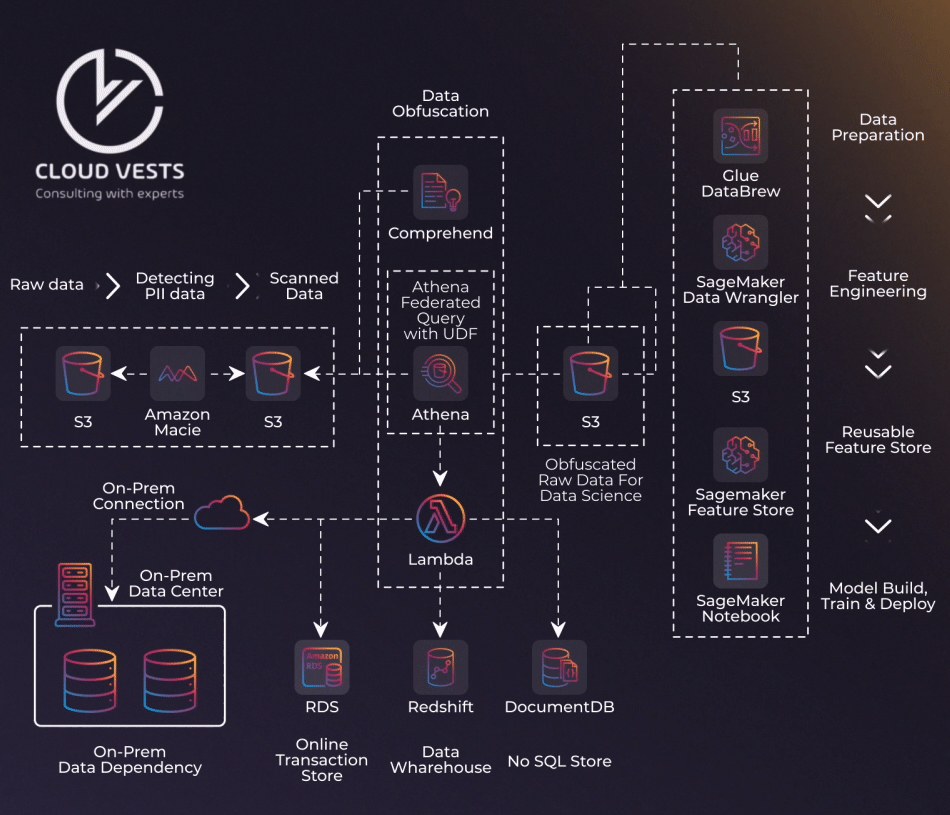
To protect PII and comply with regulations, such as CCPA, GDPR, and PCI DSS, structured and non-structured sensitive data undergo meticulous redaction in AWS data stores. This process, detailed in Figure 1, ensures data sanitization before reaching data engineers and scientists, aligning with organizational data security policies.
Architectural Walkthrough
1. Data Ingestion:
- Employ AWS DataSync, AWS Storage Gateway, and AWS Transfer Family for batch or streaming data ingestion.
- Data lands in an Amazon S3 “raw data” bucket.
2. Detecting Sensitive Data:
- Use Amazon Macie to identify sensitive data within the raw data bucket.
- Macie, a fully managed security service, tags objects with an Amazon S3 tag upon discovering sensitive data.
- Tagged data moves to a “scanned data” bucket.
3. Unstructured Data Redaction:
- Amazon Comprehend, an NLP service, redacts sensitive fields like credit card numbers and dates of birth.
- This ensures compliance and protects customer information.
Conditional Redaction and Data Integration
4. Conditional Redaction:
- Leverage Amazon S3 Object Lambda for specific redaction use cases.
- AWS Lambda functions intercept GET requests, redacting data as needed.
5. Federated Query for Data Integration:
- Use Athena federated queries with user-defined functions (UDFs) when joining datasets from different sources.
- UDFs assist in redacting data, promoting consistency.
Streamlining Data Preparation and Feature Engineering
6. Data Preparation with AWS Glue DataBrew:
- Employ AWS Glue DataBrew for code-free data preparation.
- Choose from 250+ pre-built transformations for automated tasks.
7. Feature Engineering with SageMaker Data Wrangler:
- Use SageMaker Data Wrangler for feature engineering on curated data.
- 300+ pre-configured data transformations streamline the process.
Unified Storage and ML Model Training
8. Unified Storage with SageMaker Feature Store:
- Store SageMaker Data Wrangler output in SageMaker Feature Store.
- A centralized repository for features ensures consistency during training.
9. ML Model Training:
- Use ML features in SageMaker notebooks or SageMaker Studio for model training on redacted data.
- These integrated environments facilitate building, training, deploying, and monitoring ML models.
In Conclusion
By following this architecture, financial companies can automate PII redaction, ensuring regulatory compliance and customer data protection throughout the data lifecycle.
Reference
Detecting and redacting PII using Amazon Comprehend
Use Your Code to Process Data as It Is Being Retrieved from S3
Redacting sensitive information with user-defined functions in Amazon Athena